

Разработчики все чаще используют ChatGPT, Gemini и другие нейросети, чтобы быстро получить типы TypeScript или структуры Go из готового JSON. На первый взгляд задача простая: вставил пример данных, попросил описать типы – получил готовый результат. Но именно в таких рутинных действиях скрывается опасность.
Главная проблема в том, что ChatGPT не просто копирует структуру данных. Он пытается «улучшить» ее по смыслу. Например, поле user_id может внезапно превратиться в UserId, необязательное значение – исчезнуть, а числовой код – стать строкой. Для живого проекта это не мелкая неточность, а потенциальная ошибка в сборке, проверке данных или обмене между службами.
Где чаще всего ошибается искусственный интеллект?
При создании типов из JSON нейросеть особенно часто ошибается в трех местах: названия полей, необязательные свойства и вложенные объекты. Если в примере нет одного из возможных значений, ChatGPT может решить, что такого поля не существует. Если поле выглядит «странно», модель иногда переименовывает его в более привычный вид.
Для человека это кажется удобной правкой, но для программы имя поля – точный договор. Сервер отправляет user_id, а приложение ждет userId – и данные уже не совпадают. Поэтому генерация типов через ChatGPT без проверки опасна там, где важна строгая совместимость: личные кабинеты, платежи, складской учет, отчеты, внутренние системы компаний.
Как использовать ChatGPT без риска для проекта?
ChatGPT полезен, если воспринимать его не как источник истины, а как помощника. Он может быстро объяснить структуру, предложить черновик, показать возможные слабые места. Но окончательное описание типов лучше строить на проверяемом способе: из схемы данных, из настоящего ответа сервера или с помощью инструмента, который не додумывает поля.
Практичный подход такой: сначала сохранить исходный JSON, затем автоматически извлечь из него типы, после этого проверить результат тестами. Нейросеть можно подключать на этапе объяснения и улучшения читаемости, но не отдавать ей право самостоятельно менять имена полей и обязательность значений.
Как исправить ошибки генерации типов?
Чтобы снизить риск, стоит в запросе к ChatGPT прямо запрещать изменения структуры. Например: «сохрани все имена полей без переименования», «не удаляй поля», «отмечай как необязательные только те свойства, которые явно отсутствуют в части объектов». Еще лучше – просить модель не только выдать типы, но и отдельно перечислить спорные места.
Для рабочих процессов полезно добавить проверку: сравнение ключей исходного JSON и созданного типа, запуск тестов на примерах данных, проверку вложенных объектов. Такой контроль быстро выявит, где нейросеть «помогла» слишком активно.
Автоматизация разработки с ChatGPT
В автоматической цепочке сборки и проверки любая неточность множится. Ошибка, незаметная в одном файле, может попасть в выпуск и сломать обработку данных у пользователей. Поэтому генерация типов должна быть воспроизводимой: одинаковые входные данные – одинаковый результат.
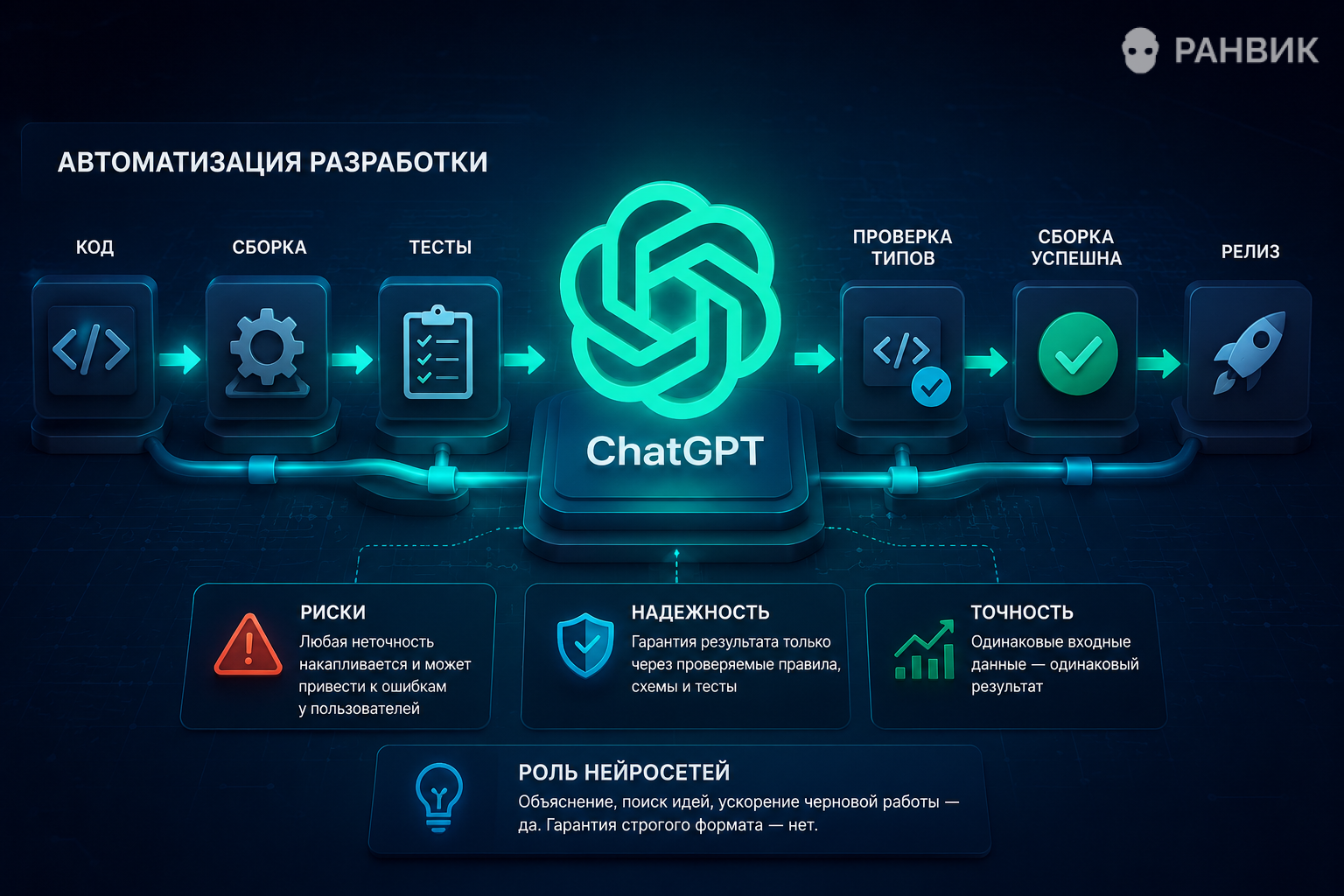
Нейросети пока не гарантируют такую точность. Их сильная сторона – объяснение, поиск идей, ускорение черновой работы. Но там, где нужен строгий формат, лучше опираться на проверяемые правила, схемы и тесты.
Экспертный вывод
ChatGPT не «плох» для программистов, но его нельзя использовать как бесконтрольный генератор типов.
Рекомендация: доверяйте нейросети объяснение и ускорение рутины, но не доверяйте ей структуру данных без проверки. В проектах, где ошибка стоит денег, генерация типов должна проходить через автоматическую сверку с исходным JSON и обязательные тесты.