

Современные нейросети давно перестали быть просто удобным окном для общения. ChatGPT, Claude и другие языковые модели показали, как быстро искусственный интеллект может писать тексты, объяснять код, помогать с поиском идей и автоматизировать рутинные задачи. Но для разработки реальных цифровых продуктов одного подключения модели уже недостаточно.
Главный вопрос теперь звучит иначе: как построить систему, которая отвечает точно, не выдумывает лишнего, работает быстро и не тратит бюджет впустую. Именно поэтому разработчикам и владельцам продуктов важно понимать базовые строительные блоки генеративного искусственного интеллекта.
Почему простого подключения ChatGPT уже мало?
Когда пользователь задает вопрос нейросети, снаружи все выглядит просто: запрос отправляется, ответ появляется на экране. Но внутри работает целая цепочка решений. Система делит текст на небольшие части, оценивает связи между ними, ищет смысл, подбирает нужный контекст и только потом формирует ответ.
Если этого не учитывать, приложение может быстро стать дорогим, медленным и непредсказуемым. Длинные запросы увеличивают нагрузку, слабая структура данных ухудшает качество ответов, а отсутствие проверки источников повышает риск ошибок.
Поэтому разработка решений на базе искусственного интеллекта – это не только выбор модели. Это архитектура, контроль расходов, грамотная работа с данными и понимание того, где модель должна отвечать сама, а где обязана опираться на внутренние документы компании.
Как снизить стоимость ответов?
Языковые модели не читают текст так, как человек. Они разбивают фразы на отдельные текстовые единицы. Именно от их количества зависят скорость обработки, стоимость запроса и объем информации, который можно передать модели за один раз.
Для бизнеса это практический момент. Если в запрос постоянно добавлять лишние инструкции, длинные описания и повторяющиеся данные, система будет работать дороже. Если же заранее продумать структуру запроса, убрать лишнее и оставить только полезный контекст, ответы станут быстрее и стабильнее.
Это особенно важно для сервисов поддержки, внутренних помощников, образовательных платформ и инструментов для работы с документами. Там каждое обращение пользователя превращается в расходы, а качество ответа напрямую зависит от того, насколько чисто и понятно сформулирована задача.
Почему ChatGPT и Claude понимают контекст?
Ключевой прорыв современных нейросетей связан с архитектурой трансформера. Ее сила в том, что модель анализирует не только отдельные слова, а связи между разными частями текста. Благодаря этому она может понимать, к чему относится местоимение, какая фраза важнее и какой смысл скрыт в длинном вопросе.
Для пользователя это выглядит как «понимание контекста». Для разработчика – как возможность строить более сложные сценарии: помощников для поиска по базе знаний, анализаторов обращений, советников для сотрудников, систем проверки документов и инструментов для работы с кодом.
Но здесь есть важное ограничение. Даже сильная модель не гарантирует правильный ответ, если ей не дали нужные данные. Она может красиво сформулировать мысль, но ошибиться в фактах. Поэтому качественная архитектура приложения должна не только отправлять вопрос в нейросеть, но и подставлять проверенную информацию.
Как искусственный интеллект находит ответ по смыслу?
Обычный поиск часто зависит от точного совпадения слов. Если клиент пишет «как вернуть деньги», а в базе знаний указано «оформление возврата», простая поисковая система может не увидеть связь. Нейросети решают эту проблему через смысловые векторы.
Смысловой вектор превращает текст в числовое представление, где похожие по значению фразы оказываются близко друг к другу. Благодаря этому приложение ищет не только слова, а намерение пользователя. Это полезно для справочных разделов, корпоративных документов, интернет-магазинов, обучающих платформ и внутренних баз знаний.
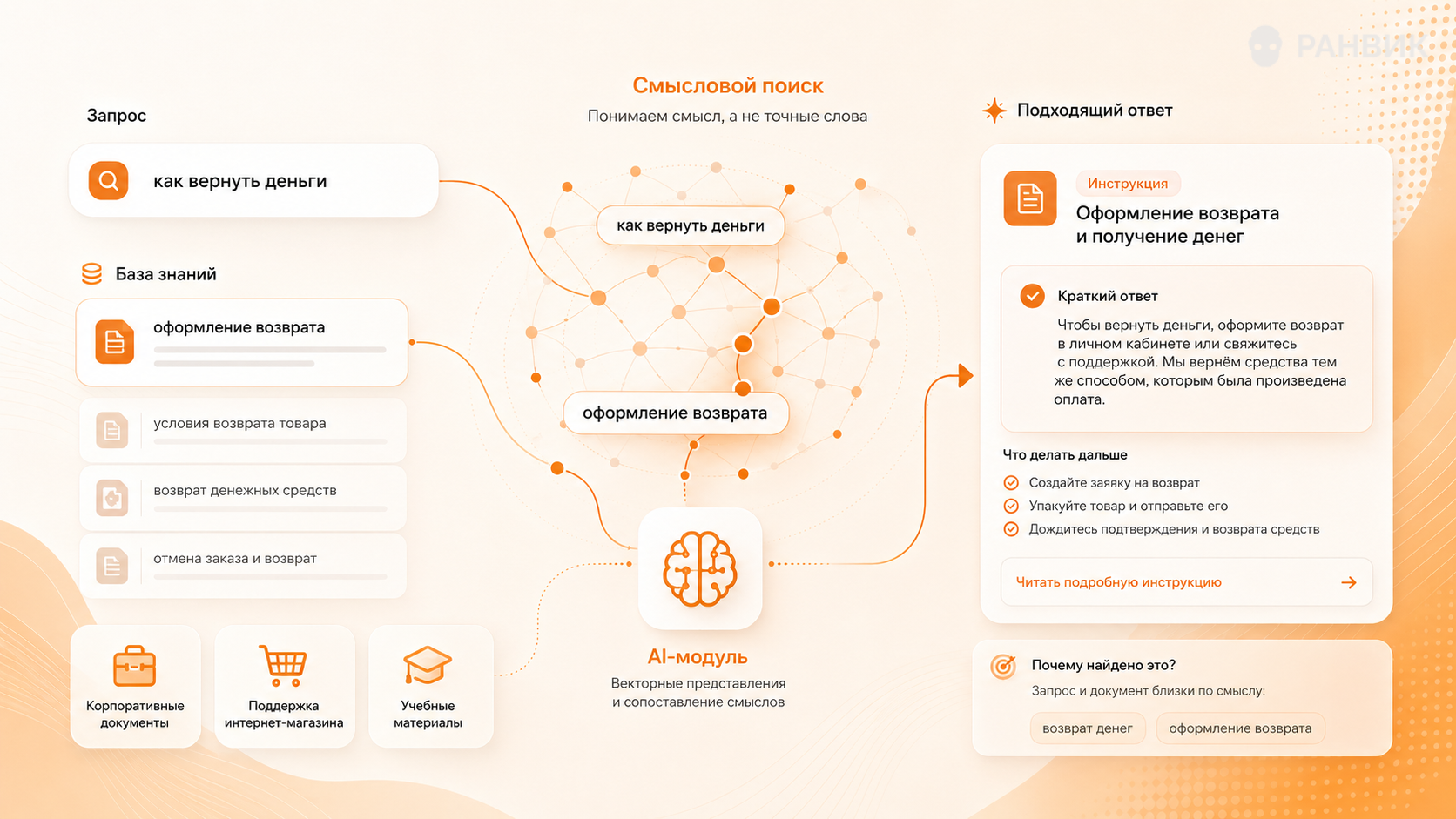
Такой подход делает искусственный интеллект гораздо полезнее в реальной работе. Он помогает находить нужный документ даже тогда, когда пользователь формулирует вопрос своими словами.
Зачем нужен поиск по базе знаний перед ответом?
Одна из главных ошибок – считать, что языковая модель «знает все». На самом деле она не знает свежие внутренние правила компании, закрытые документы, актуальные тарифы, договоры, инструкции и изменения в процессах.
Поэтому в корпоративных решениях все чаще используется схема, при которой система сначала ищет нужные данные в базе знаний, а уже потом передает их модели для формирования ответа. Так нейросеть не фантазирует, а опирается на конкретные документы.
Например, если покупатель спрашивает, можно ли вернуть поврежденный товар через 45 дней, приложение должно не угадывать, а найти актуальные правила возврата и сформировать ответ на их основе. Это снижает риск ошибок, повышает доверие и делает искусственный интеллект пригодным для серьезных бизнес-задач.
Экспертный вывод
Нейросети уже стали частью разработки, но главный результат дает не самая громкая модель, а правильно собранная архитектура.
Рекомендация: перед внедрением ChatGPT, Claude или другой языковой модели сначала опишите реальные задачи, подготовьте базу знаний и настройте проверку ответов. Такой подход даст больше пользы, чем простое подключение искусственного интеллекта ради тренда.